
이번 논문은 ICLR 2025에 등재된 논문으로, LLM을 이용한 Zero-shot Re-ranker를 효율적으로 사용하기 위해 Attention Weight을 이용하는 방법을 제시한 논문입니다.
결론
결론부터 살펴보고 가면, 이 논문에서는 In-Context Re-ranking (ICR) 방법을 제시하고, 기존 방식보다 높은 점수를 받았음을 보여줍니다. 기존 Generative 방식과 비교했을 때, O(N)의 forward passes로 인한 latency를 O(1)으로 획기적으로 감소시켰다는 점이 인상적입니다.
LLM-based re-ranking
LLM의 등장은 Information Retrieval (IR) 생태계에 지대한 영향을 주었습니다. 특히 LLM을 이용한 zero-shot re-ranking의 retrieval 능력이 매우 좋은 성능을 주기에 그 영향은 더욱 커져갑니다.
하지만, 기존 LLM 기반 re-ranking 방식들은 거의 LLM의 생성 능력에 많이 의존하는 편입니다.
현존하는 re-ranking 방식은 크게 3가지로 분류됩니다.


- Listwise re-ranking : LLM이 ranking list를 생성하도록 지시하는 방식입니다.
- 가장 직접적인 접근 방식이지만, 답변 누락 / hallucination / unstructured output 등의 이슈가 있습니다.
- Pairwise re-ranking : 우선 LLM이 쌍으로 이루어진 document들을 각각 비교한 후, 종합 랭킹에 통합하는 방식입니다.
- Pointwise re-ranking : LLM이 query에 대한 모든 document들의 관련성을 각각 비교하면서 점수를 부여하는 방식입니다.
- Pointwise 방식은 주로 relevance generation이나 query generation을 통해 진행됩니다. (Liang et al., 2023)
- Pairwise / Pointwise 방식은 LLM이 black-box 성질을 갖고 있기 때문에 점수를 보정하는 게 어렵다는 단점이 있습니다.

위에서 제시한 3가지 방식은 공통적으로 가지고 있는 단점이 있습니다.
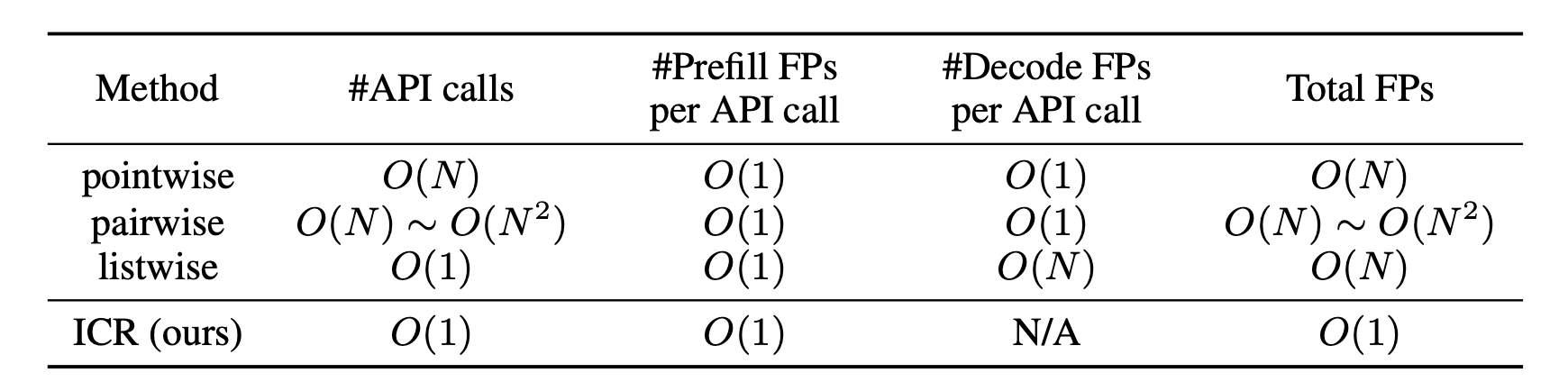
- N개의 documents를 re-ranking 하기 위해서 O(N)~O(N^2) API 호출이 요구됩니다.
- LLM에 의해 생성된 관련도 점수를 해석하기 어렵기 때문에, re-ranking 과정의 신뢰도를 떨어뜨립니다.
- LLM이 항상 올바른 구조의 출력을 생성한다는 보장이 없습니다. (특히 relevance scores, ranking list 생성 시)
또한, LLM-based zero-shot re-ranking을 가능케 하기 위해, re-ranking 합성 데이터를 이용하여 Foundation Model을 re-ranking에 특화시키는 시도 또한 진행했습니다 (ex. FIRST).
하지만 이 방식들 또한 추가적인 fine-tuning을 해야 한다는 점, 그리고 학습에 사용된 데이터들의 도메인이 아니면 답변 정확도가 떨어진다는 문제를 갖고 있습니다.
Research Question & Hypothesize
위에서 볼 수 있듯이, LLM의 생성 능력에만 의존한 generative approach에는 한계가 있습니다.
이에 연구진들은 다음과 같은 질문을 던집니다.
Is auto-regressive generation necessary and optimal for LLMs to perform re-ranking?
LLM을 이용한 re-ranking을 위해선 auto-regressive 방식의 생성이 필수적인가? 이것이 최적인가?
그리고 위 질문에 대한 가설을 제시합니다.
re-ranking과 관련된 의미 있는 신호들은 LLM의 Context Encoding 단계에서 많이 등장할 것이다.
generative approach 대신 이 신호들을 직접 활용한다면 re-ranking 성능을 향상할 수 있을 것이다.
In-Context Re-ranking

연구진들은 이 신호를 attention weight에서 발견하였고, 이를 기반으로 in-context re-ranking (ICR) 방식을 제안합니다.
기존 방식과 비교했을 때, ICR은 N개의 document를 re-ranking할 때 오직 2개의 forward pass만 필요하기 때문에,
API 호출 시간복잡도가 O(1)이라는 점에서 강력한 특징을 가집니다.
또한, LLM의 attention weight로부터 re-ranking과 관련된 의미 있는 신호들을 파악할 수 있었다고 합니다.
예를 들면, query와 passages 간의 contextualization signals, 모순 관계를 처리할 때의 reasoning signals, bridge entities 간의 information integration signals 등이 있죠.
이를 통해, LLM 기반의 re-ranking을 위해선 generative 방식이 절대적 방법이 아니라는 것을 보여주며 가설을 뒷받침하고,
open-weight 모델들을 더 잘 활용할 수 있는 방법을 제시한다는 점에서 많은 의의가 있는 논문입니다.
Method

In-Context Re-ranking (ICR)은 크게 3단계로 진행됩니다.
1단계 : LLM Prompting
attention weights을 얻기 위해, LLM에 document와 search query를 주며 query에 맞는 답을 출력하라는 프롬프트를 작성합니다.
논문에서는 LLM에서 흔히 볼 수 있는 Question Answering (QA) 작업과 Information Extraction 작업에 대해 진행했습니다.
LLM의 position bias 현상을 타파하고자 query 내용을 프롬프트 마지막에 작성한 점이 인상적입니다.
< QA 지시 프롬프트>
<prefix>Here are some paragraphs. Please answer the question based on the relevant information in the paragraphs.
[1] Document 1 Christopher Allen Sale (born March 30, 1989), nicknamed The Condor, is an American professional baseball pitcher ~~~
...
[20] Document 20 Klay Thompson Klay Alexander Thompson (born February 8, 1990) is an American professional basketball player ~~~
Query: What relationship does Fred Gehrke have to the 23rd overall pick in the 2010 Major League Baseball Draft?<suffix>
<IE 지시 프롬프트>
<prefix>Here are some paragraphs.Please find information that are relevant to the query.
[1] Ukraine and the United Nations
The Ukraine ~~
...
[20] Council of People's Ministers
The Council ~~~
Query:Ukrainian Soviet Socialist Republic was a founding participant of theUN.<suffix>
2단계 : Attention Aggregation
"LLM은 쿼리를 처리할 때 관련 있는 documents들의 토큰에 평균적으로 더 강한 가중치를 줄 것이다"의 가설처럼,
연구진들은 documents 내 각 토큰이 쿼리로부터 받는 어텐션 가중치를 계산하기 위해 가중치를 전부 합해버리는 방식을 설계했습니다.
이에 따라, LLM의 L번째 층, H번째 attention 헤드에서 i번째 document를 이루는 토큰들 중 j번째 토큰에 대한 ranking score는
다음과 같습니다.

공식에서 사용하는 I_q는 쿼리 Q에 대한 토큰 인덱스 집합을 뜻합니다. 공식을 다시 보면, 모든 층, 모든 어텐션 헤드에서 쿼리 Q에 대해 i번째 document와의 어텐션 가중치 합이라는 것이라 이해할 수 있습니다. (저는 이해하는데 1시간이나 걸렸네요;;)
그리고, 각 쿼리 토큰의 어텐션 가중치 합은 항상 1이라는 특징 때문에, 이 Attention Aggregarion 전략은 length bias 이슈(더 긴 document가 더 높은 점수를 받는 편향)를 피한다는 것 또한 언급하고 넘어가네요.
코드로 살펴봅시다.


_get_attn_weights를 통해 query_states와 key_states 간의 내적을 이용한 어텐션 가중치 (attn_weights) 행렬을 리턴함을 확인할 수 있습니다.
이를 score_documents 메서드에서 layer 만큼 반복하면서 최종 리스트에 누적시킴을 볼 수 있습니다.
3단계 : Ranking Score Calibration
이 단계는 LLM의 다양한 편향을 보정하기 위한 단계입니다.
이상적인 re-ranker는 아무 내용도 없는 쿼리에 대해 모든 documents에 동일한 점수를 부여해야 한다는 점에서 착안하여 가중치 값을 보정하는 단계입니다.
먼저, "N/A"라는 아무 내용도 없다는 쿼리 (Q_cal)을 사용해서 어텐션 가중치를 계산한 후 ranking score를 얻습니다.
그 후, 2단계에서 구했던 실제 쿼리로부터의 ranking score 점수에서 "N/A" 쿼리에 대한 ranking score를 빼서 보정된 점수를 얻습니다.

마지막으로, i번째 Document에 대한 attention weights들 중, 비정상적으로 낮은 calibration 점수를 보이는 것들은 가중치 합에서 제외함으로써 최종 점수를 얻습니다. 이는 추후 discussion에서 다시 한번 언급하지만, calibration 점수가 base LLM의 intrinsic bias를 잘 보여주기에 제외할 수 있다고 언급합니다.
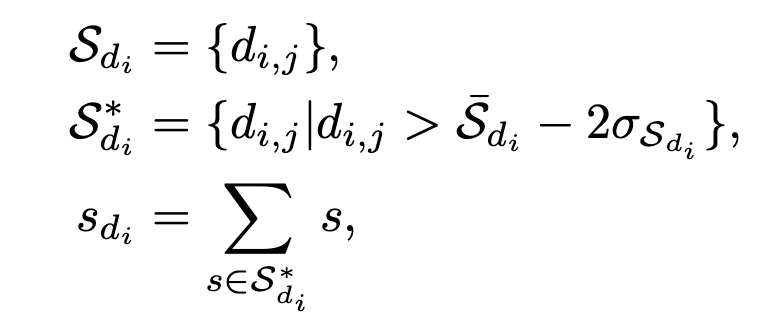
Experiments
논문에서는 ICR 방법을 평가하기 위해 open-weight LLM을 사용한 single-hop과 multi-hop re-ranking 작업을 각각 관찰했습니다. 이뿐만 아니라, 효율성과 성능에 대한 scaling 트랜드를 평가하고, ICR에서의 attention aggregation과 calibration 과정의 효율성도 보여주고자 합니다.
또한, zero-shot baseline 모델로는 RankGPT로 선정했는데, 이는 추가적인 학습비용이나 추론비용이 들지 않는 모델 중 가장 대표적인 모델이기 때문이라고 합니다.
- Base LLMs : open-weight LLM들 중 Mistral 7B와 Llama-3.1 8B로 선정했습니다.
- Datasets
- Single-hop : TREC, BEIR (9개의 public datasets)
- Multi-hop : MuSiQue (answerable), 2WikiMultiHopQA, HotpotQA
- Metrics
- Single-hop : BM25 (for re-rank the top 100 documents), nDCG@10 (measure)
- Multi-hop : ColBERT v2 (for re-rank the top 20 retrieval results), recall@2 / recall@5 (measure)
Single-Hop Re-ranking
GPT-3.5 Turbo나 GPT-4o mini 같은 주류 모델에 비해, RankGPT와 같은 open-weight LLM은 지시 수행률에 있어 상대적으로 낮은 성능을 보입니다. 하지만 ICR은 open-weight LLM을 이용하더라도 견줄만한 성능을 보이기에 더욱 많은 의미를 가집니다.

표에서 볼 수 있듯이,
Mistral 7B, Llama-3.1 8B에서의 RankGPT와 비교했을 때 ICR이 대체적으로 더 좋은 점수를 가지는 것을 알 수 있습니다.
특히, 우측의 Micro-Avg는 두 모델에서 각각 13.3p / 8.4p, Macro-Avg는 6.5p / 0.5p 높은 점수를 보이며 ICR의 성능을 여실히 보여주고 있습니다. 표 하단의 RankGPT (GPT-3.5 turbo / GPT-4o mini) 와도 비교했을 때 비슷하거나 더 좋은 점수를 보인다는 점에서 open-weight LLM으로부터의 re-ranking 신호를 활용할 수 있다는 잠재력도 확인할 수 있습니다.
재밌는 점은, Mistral 7B는 Llama-3.1 8B와의 RankGPT 성능이나 Success Rate를 비교하면 현저하게 낮은 성능을 보인다는 것을 알 수 있는데, ICR은 오히려 성능이 더 낮은 Mistral에서 더 큰 성능 폭을 보이고 있습니다. 위에서 말한 것처럼, ICR은 text generation과 무관한 방법이기에, 낮은 text generation을 보이는 모델에서도 re-ranking 신호들을 효율적으로 활용하고 있음을 확인할 수 있는 셈입니다.
한편, ICR은 FiQA, SciFact, 그리고 FEVER에서 특히 더 좋은 점수를 받았는데,
FiQA는 검색된 패시지의 정확한 의미나 관련성은 원래 질문인 쿼리와 함께 읽어야만 완전히 이해될 수 있기에, 높은 점수는 ICR이 복잡한 re-ranking 작업에서도 더 효율적인 성능을 보인다는 것을 나타내고,
SciFact와 FEVER은 패시지가 특정 사실을 지지하거나, 아니면 모순되기 때문에, 여기서의 높은 점수는 좋은 추론 능력을 가지고 있음을 나타냅니다.
반면에, ICR이 다소 낮은 점수를 보이는 벤치마크도 있습니다. 바로 DBPedia-Entity인데, 이는 ICR의 단점 중 하나인 '어휘적 편향 (lexical bias)'에 기인한 결과라고 추정합니다. 주로 쿼리와 높은 어휘 중복을 보이는 방해 문서가 존재할 때 ICR의 성능을 저하하는 현상인데, DBPedia-Entity에서 흔히 발생하는 현상이라고 합니다.
Multi-Hop Re-ranking

Multi-Hop Re-ranking에서도 Single-Hop과 비슷한 경향을 보여줍니다.
3개의 벤치마크 데이터에 대하여, ColBERT v2로부터의 retrieval 결과들을 re-ranking 진행했을 때 RankGPT와 ICR 모두 대체적으로 향상된 점수를 얻었습니다. Single-Hop과 비슷하게, ICR이 RankGPT보다 모든 항목에서 더 높은 점수를 받았다는 점이 인상적입니다.
(R@2에서는 5~6%, R@5에서는 2~4% 더 좋은 점수를 받았네요.)
또한, RankGPT (GPT-3.5 Turbo / GPT-4o mini)와 비교했을 때도 거의 동일한 점수를 보여준다는 점에서도 ICR의 강점을 뒷받침해줍니다.

Multi-hop Re-ranking에서의 성능을 더욱 잘 이해하기 위해, 연구진들은 All-Recall@5 값도 함께 비교했습니다. 일반적인 Recall@K가 상위 K개 결과 내에 관련 문서가 하나라도 포함되면 성공으로 보는 반면, All-Recall@K는 모든 관련 문서가 상위 K개 내에 포함되어야 성공으로 간주하는 더 엄격한 지표입니다.
이 때에도 ICR이 대체적으로 RankGPT보다 좋은 점수를 받음으로써 documents간의 관계를 더욱 잘 이해하고 있다는 것을 보여줍니다.
Scaling Trend of Speed and Performance

이전에 언급했듯이, O(N) 개의 forward pass를 가지는 RankGPT에 비해, ICR은 오직 2개의 O(1) forward pass만 필요로 합니다.
이는 당연히 latency 성능에도 직결되기에, K개의 documents를 re-ranking할 때의 RankGPT와 ICR의 속도 차이를 비교해봤습니다.
그래프에서 볼 수 있듯이, ICR이 RankGPT보다 최소 2배 이상 빠른 Latency를 보입니다. 그러면서도 RankGPT는 K=40 이상부터는 성능이 향상되지 않는 반면, ICR은 꾸준히 향상되고 있음을 보여줍니다.
Attention Aggregation과 Calibration 과정의 효율성
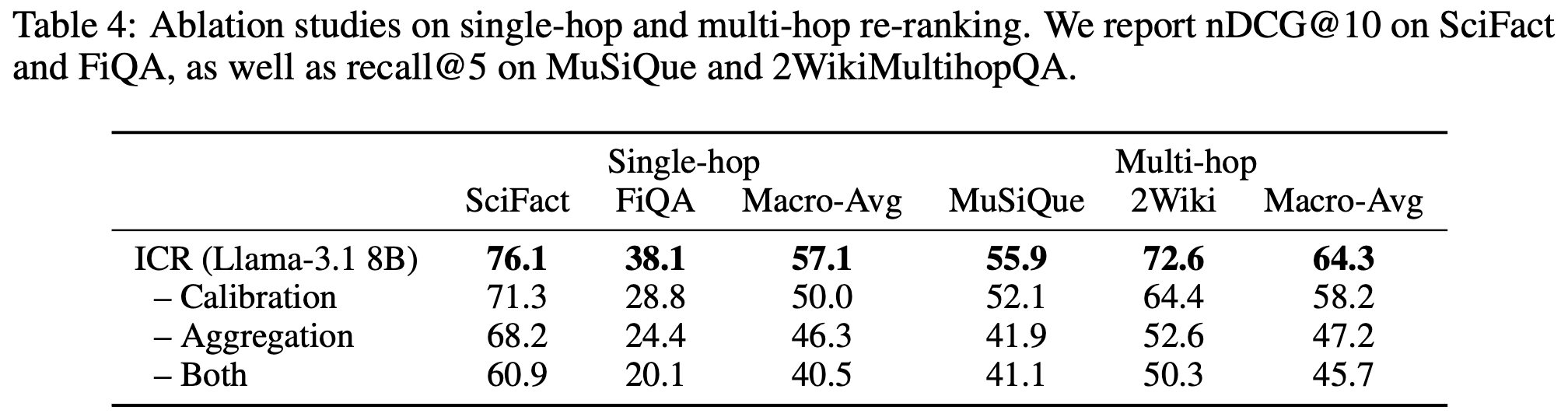
마지막으로, ICR의 Attention Aggregation과 Calibration 각각의 과정이 re-ranking 성능에 어느 정도 영향을 주는 지 확인하고자 각 과정을 제거한 버전과 포함한 버전 간의 점수 비교를 진행했습니다. (Ablation Study)
표에서 볼 수 있듯이, Aggregation, Calibration을 각각 제거한 버전과 포함한 버전 간 많은 차이가 벌어짐을 볼 수 있습니다. 이것이 각 과정이 ICR의 좋은 성능을 위한 필수적인 요소임을 뒷받침합니다.
Discussion
1. Calibration이 ICR 성능을 높일 수 있는 이유
앞서 Method에서도 설명했듯이, "N/A" 쿼리를 이용한 Calibration 방법은 이상적인 re-ranker는 아무 내용도 없는 쿼리에 대해 모든 documents에 동일한 점수를 부여해야 한다는 점에서 착안했습니다. 그러므로, calibration 점수에서 특정 점수가 균일한 분포를 벗어났다는 것은 곧 base LLM의 내적 편향을 반영하고 있습니다.

평가에 사용된 20개의 Document에 대한 calibration ranking score를 확인해보니, 좌측 그래프처럼 초반부나 후반부에 입력된 document들의 점수가 평균으로부터 멀리 있음을 알 수 있습니다. 이를 통해 lost-in-the-middle 이슈와 같은 position bias가 기존 LLM에서 나타나고 있음을 유추할 수 있습니다.
ICR의 Calibration score는 이러한 bias들을 보정해줌으로써 RankGPT에 비해 더 나은 성능을 보일 수 있습니다.
또한, ICR은 모든 토큰들로부터의 ranking score를 합하여 관련도를 결정하기에, 이 점수들은 ICR의 내부 연산 과정을 직접적으로 나타내기도 합니다.
이러한 특징 덕분에, 우측 예시 문단에서 볼 수 있듯이, 기존 LLM 모델의 intrinsic bias들을 calibration ranking score로부터 잡아낼 수 있습니다. 예시 문단처럼, Llama3.1 8B는 문단의 Title, Entity, Punctuation 에 더 많은 가중치를 주는 편향성을 가짐을 알 수 있습니다.
2. ICR은 어떤 Re-ranking 시그널들을 활용할까?
실험 결과를 비춰볼 때, ICR은 RankGPT보다 대부분의 single-hop 데이터셋 (FiQA, FEVER, SciFact)과 모든 multi-hop 데이터셋에서 높은 성능을 보였습니다.
Query-Passage Contextualization (쿼리와 패시지 간 문맥화)
BEIR 벤치마크 중 FiQA는 다른 데이터셋과는 달리 쿼리에 대한 답변을 인간이 작성했기에, 패시지만 보고 독립적으로 적정한 정보를 찾기 어렵고, 쿼리와 패시지 간의 문맥을 이해해야 올바른 정보를 추출할 수 있습니다. 때문에 보편적인 QA 데이터셋보다 더욱 복잡함을 요합니다.

ICR은 이런 FiQA에서 매우 강점을 보였습니다.
위의 그림은 "How to read bond yield quotes? What do the time, coupon, price, yield, and time mean?" 이라는 쿼리에 대해, BM25(B), RankGPT(R), ICR (I)가 매긴 랭킹을 보여줍니다. 쿼리 자체가 bond yield quotes를 읽는 법, time, coupon 등의 단어가 의미하는 정의를 질문하고 있다는 것을 알 수 있습니다.
첫 번째 패시지를 보면, RankGPT는 10등으로 매긴 반면, ICR은 1등으로 점수를 부여했습니다. 이는 단순히 쿼리에 들어있는 단어 토큰이 해당 패시지에 많이 들어있어서 나온 결과가 아니라, "Coupon is", "Price is", "Yield is" 와 같이 "is" 라는 토큰 또한 이해함으로써, 해당 내용에서는 Coupon / Price / Yield 에 대한 정의를 알려주는 패시지라는 것을 이해하고 있음을 알려줍니다. 실제로 해당 패시지는 쿼리에서 묻는 정보들을 대부분 담고 있죠.
이에 비해, 두 번째 패시지는 RankGPT는 1등, ICR은 2등으로 부여했습니다. 패시지 내에선 쿼리에서 나온 The, coupon, quoted 등의 단어가 많이 나오긴 하지만, 쿼리가 묻는 정보와는 적합하지 않음을 알 수 있죠.
ICR이 이러한 덜 관련 있는 패시지에 대해서는 더 약하고 분산된 어텐션 패턴을 보였다고 설명합니다
Contradiction-Based Reasoning (모순 기반 추론 능력)
연구진들은 ICR이 특히 검색된 구절과 모순되는 주장에 대해 잘 작동한다고 설명합니다. FEVER 벤치마크 데이터셋에 대해, ICR은 Contradiction 예시들에 대해선 RankGPT보다 26% 더 나은 성능을 보이는 반면, 지지 (Support) 예시들에 대해선 9% 더 나은 성능을 보입니다.
이러한 이유에 대해, 쿼리와 모순되는 주장을 가지는 패시지들은 어휘 중복성이 더 낮기 때문에 추론 과정이 어렵지만, ICR은 RankGPT 보다 모순되는 패시지들을 효율적으로 추론한다는 것을 알 수 있습니다.

예시를 보면, 특정 영화의 감독이 Krzysztof Kieslowski라는 쿼리에 대해, 모순되는 정보를 지닌 첫 번째 패시지에 BM25, RankGPT는 각각 11위, 28위를 부여했으나, ICR은 모순된 패시지임을 파악하고 1위를 부여했음을 보여줍니다. 실제로 패시지에서는 해당 영화의 감독이 다른 사람임을 나타내고 있죠.
Multi-Hop Information Integration

ICR은 여러 패시지들을 관통하는 통합된 정보를 요구하는 multi-hop 작업에서 강력한 성능을 보입니다.
토큰 단위의 분석을 통해, 연구진들은 ICR이 특히 정보 통합 과정에 가장 중요한 bridge entity 토큰에 높은 랭킹을 부여한다는 것을 발견했습니다. 예시에서도 볼 수 있듯, First Hop과 Second Hop을 통합할 때 bridge 역할을 하는 Frederick Douglass 엔티티 토큰에 강하게 점수를 부여하고 있음을 볼 수 있죠.
이를 통해, ICR은 LLM의 multi-hop 추론 시그널도 활용하고 있음을 제시합니다.
Limitation
1. Lexical Bias (어휘 편향) 에 대해선 계속 어려워하고 있다.
ICR의 한계 중 하나는 Document 내 소수의 토큰과, 일부 Document에 대부분의 re-ranking 점수가 집중된다는 특성이 있습니다.
이로 인해, 대부분의 다른 문서는 점수를 거의 받지 못해 서로 구분이 어렵게 됩니다.
또 다른 한계로, 이러한 신호가 쿼리와 어휘적으로 유사한 구문에 대부분 집중된다는 경향이 있습니다.
이러한 어휘 편향 이슈는 문서 관련성이 단순 어휘적 유사성을 넘어선 문맥 간 유사성을 요할 때 성능 저하로 이어집니다.
평가에서도 DBPedia-Entity에서 이러한 문제가 성능 저하로 이어짐을 볼 수 있었습니다.
2. Open-weight LLM에서만 사용할 수 있기에, API 접근만 가능한 주류 LLM들에는 제한적인 방법이다.
ICR 기반의 re-ranking이 좋은 성능을 보여주지만, 아직까지는 현재 주요 LLM들을 이용한 RankGPT가 가장 좋은 성능을 냅니다.
References.
1. Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
2. Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting
'Programming > NLP,LLM' 카테고리의 다른 글
| [1편] 인공지능 발전에 큰 획을 그은 전설의 3대 논문 - Computing Machinery and Intelligence (0) | 2025.10.04 |
|---|---|
| [Paper Review] Ignore Me But Don't Replace Me (0) | 2025.02.17 |
| Multi-Head Attention (0) | 2025.01.22 |
| [리뷰] GPT-4 for Defense specific Named Entity Extraction (3) | 2024.01.04 |
| Transformers Architecture (1) | 2024.01.03 |